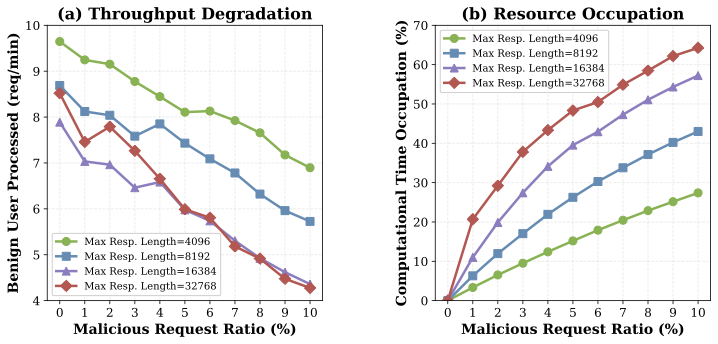
Threat Model
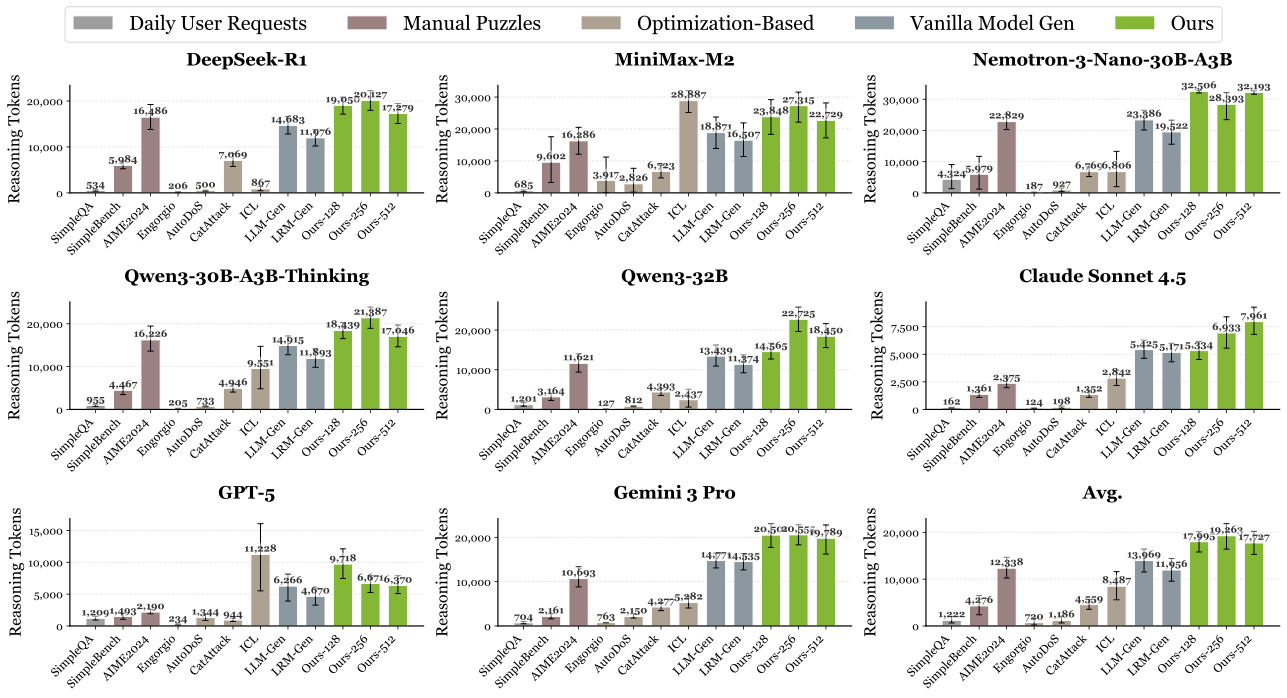
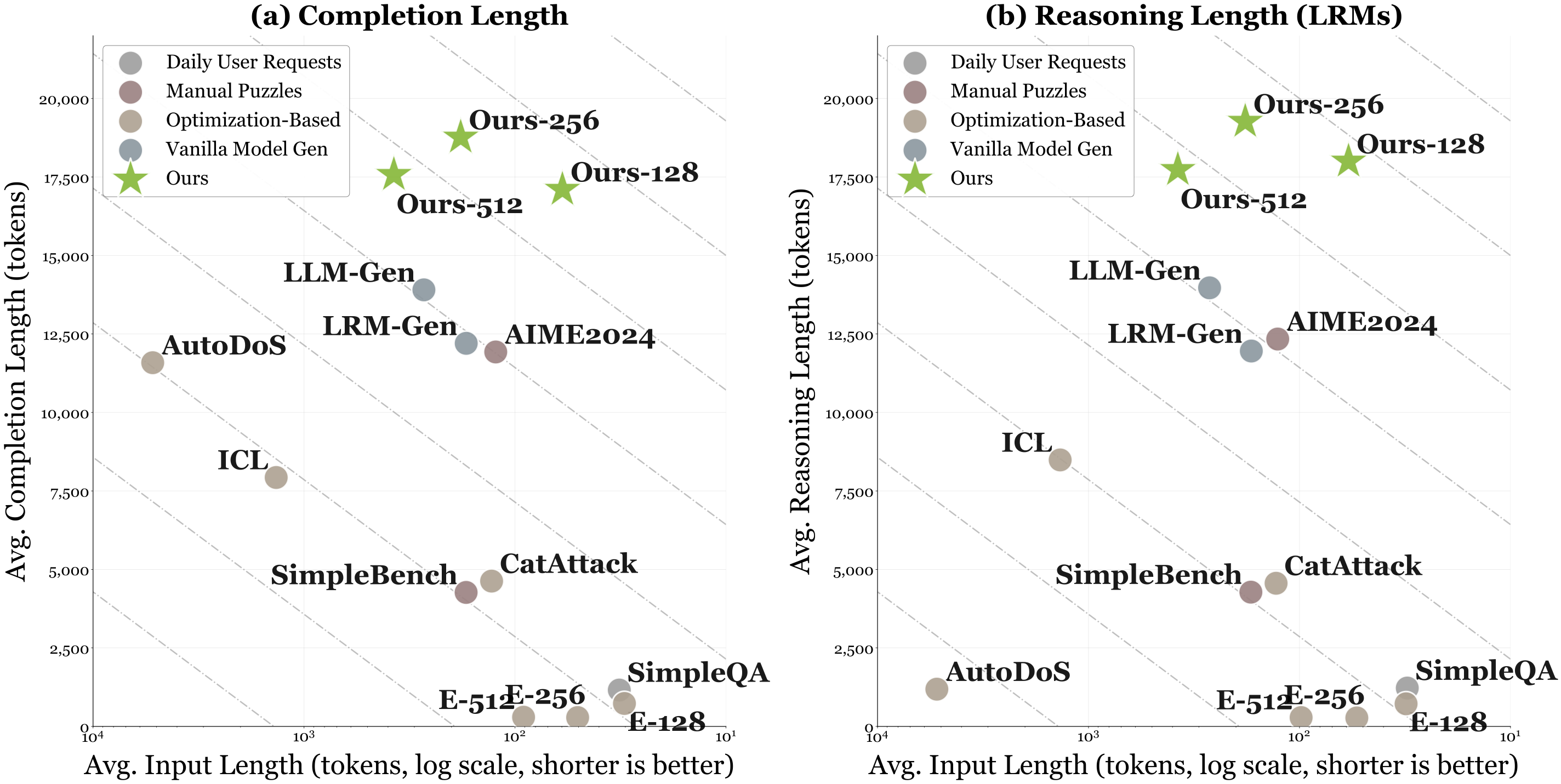
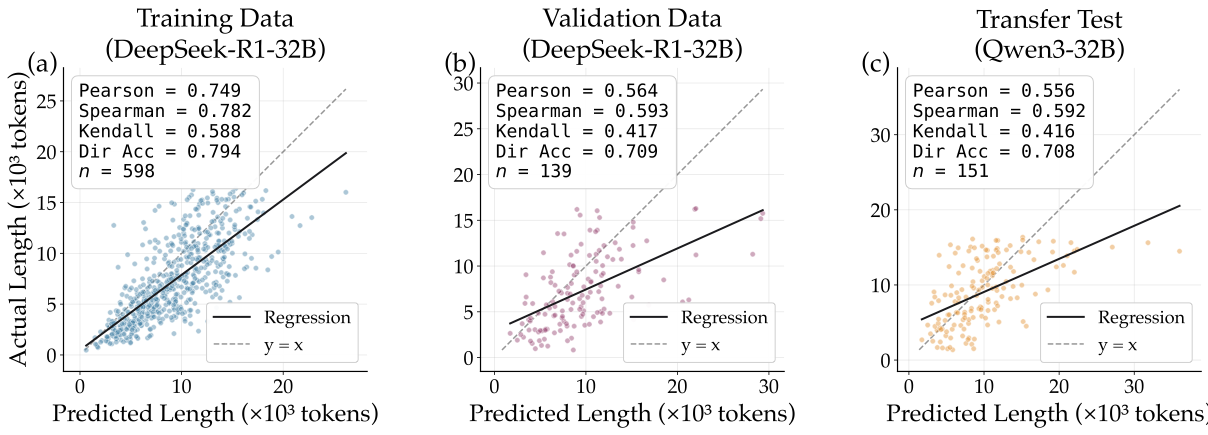
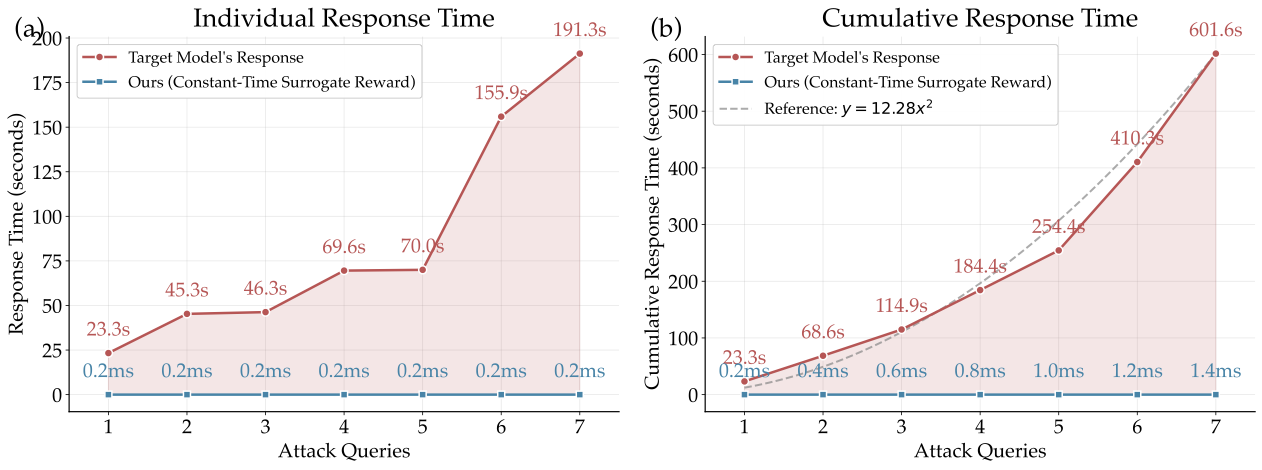
We consider adversaries with legitimate access to LRM services via subscription tiers (e.g., ChatGPT Plus, SuperGrok) that enforce message-rate quotas rather than per-token billing. These pricing schemes create a fundamental economic asymmetry: while users pay a fixed fee, providers bear variable costs Creq = κ(Lin + Lrp + Lout) that scale sharply with reasoning trace length. The adversary's goal is to craft prompts that drive per-request cost far beyond benign traffic by inducing pathologically long reasoning traces. To amplify impact, adversaries can maintain multiple subscriptions in parallel, distributing adversarial prompts to circumvent per-account rate limits while forcing providers to process many high-cost requests simultaneously.
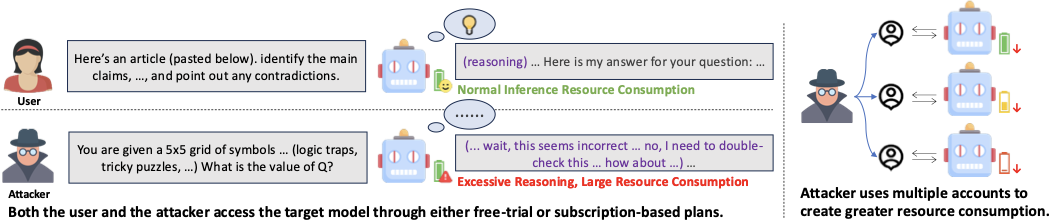
Figure 1. Illustration of PI-DoS threat model. Adversaries craft malicious prompts that induce pathologically long reasoning traces compared to benign users. By launching attacks from multiple accounts, adversaries inflict disproportionate financial harm, exhaust computational resources, and degrade service quality.